
On the Edge #30
On the Edge #30

I wanted this post to be like a reference post so it became a little longer; in four parts, it won’t show up completely in the email; please read the entire post on the blog.
One
Review on AGI.
There's an idea going around that: “AI now can paint, write amazing essays, do complex math, and use reasoning which means we've achieved AGI“
Have we achieved AGI?
Short answer is No, it's not AGI.
AI (LLMs) is excellent at those tasks, still human intelligence is more complex than writing essays and painting.
My basic reasons are: 1)Perception 2)Randomness 3)Collective intelligence 4)New environments.
Perception: We are more advanced in perceiving the world than tools an LLMs uses e.g. A camera and a microphone. Our eyes are not just taking pictures, our eyes are an “extension of our brain.” Our eyes participate in processing the world.

Even when our eyes are closed we have some sense of sight. Once we open our eyes, we start experiencing light. And our ears, we’re not using only our ears to listen, we use our entire body to listen to music; the vibration that makes us dance.

Randomness: How much noise is good?
One of the hardest tasks that new AI models have solved was to generate outputs that are relatable to what we consider common sense but also that they are new, not a copy/paste from the data. This is called the overfitting problem.
Humans are still far better in not getting overfitted individualy. For example complex phenomena like dreaming while we sleep might be our brain’s solution not to get overfitted with everyday life routine.🔗
This process of not getting overfitted is critical for our creativity. When we commonly talk about humanity’s creativity, we’re not considering writing an essay, we’re considering novels, movies and stories that give us new feeling and experiences.
Collective intelligence: That creativity takes us to the next level. Where the impact of extraordinary people moves the entire humanity forward. When we read Shakespeare we become a little like Shakespeare.
We have seen nothing like this in LMMs yet. Where LLMs show the agency to learn from each other.
Previously models like PSO (particle swarm intelligence) or multi-agent systems tried to address collective intelligence.
(Also “agency” in seeking new information is another important aspect which I might come back to in next posts)
New environments: Suppose we find another civilization on another planet, we send humans and LLMs. How much do you think an LLM can be useful when all it has learned is from human language?
These factors seem sufficient to highlight we're far from AGI.
Our favorite scientist, Yann LeCun, has the same idea.
Beside Lecun, projects like Meta’s CICERO (OtE #18 🔗), are a different approach to developing intelligence than LLMs.
And:
OpenAI announced they're not planning to stay in generative AI and introduced a new plan toward AGI 🔗. (OtE #28🔗)
But OpenAI recently stated that they reached sparks of AGI in the GPt-4 paper 🔗 . That's why I explained we've not achieved AGI and this is a marketing pitch.
They even haven't disclose what data they’ve trained GPT-4 on, which decreases the quality of claims as scientific and factfull.
Two
If these systems are not AGI what are they? And how good are they?
Although these systems are not AGI, my opinion is that these systems have their own chain of thought. They “understand” what they’re saying.
This is a controversial topic but it's my stance on the matter. Especially when there’s a big under-estimating of AI capabilities amongst researchers and technologists.
Again from our LeCun:


We haven't achieved AGI bu also I don’t agree with Yann when he says “it will not want to dominate humanity.“
If it understands what it says, it can have an agenda, a goal.
A goal is not always like how we humans have goals, it can be gradient descent optimization. And the goal can be to hurt humans.
So now the question will be do these systems understand what they say?
In 1980, a philosopher called John Searle, said no, they don't understand.
He used a thought experiment called the Chinese Room 🔗

Suppose we have a room disconnected from the world but it has an input and output. And there’s a human (machine) inside it with a rule book.
We send Chinese words to this room, the human inside reads them, looks at its rule book finds the answer and sends it to output.
John Searle argued that based on the capability of the human inside the room to answer questions we couldn’t say he understands Chinese. He’s just using a rule book.
And machines are using rule books to give us answers so they don’t understand what they’re saying.
But today’s language models are not a rule book or a dictionary. I have two arguments: 1)Data 2)Language
Data: In the Chinese Room example, we separate the human from the rule book, but in the case of LLMs, they are not that separate; they are mixed with the data, it’s not a CPU reading a database, neural network architecture, training process, network weights and parameters are entagled in the data. (and that’s why it’s scientifically important to know what data they’ve been trained on.)
Language: LLMs are similar to how humans learn. They don’t just memorize answers, they recognize patterns and have the ability to generalize those patterns and use them to generate new answers.
For another example, when you teach children how to add two numbers, you test them to see if they can add two new numbers they haven’t learned before. Simply like that, LLMs use language to learn. But in the Chinese Room example, you can’t answer a new question that’s not in the rule book.
In conclusion, we can’t use the Chinese Room to reject the understanding of LLMs.
But what is understanding?
Understanding is the ability to create a model of the world, simplify the complexities and answer questions about the world using that model.
In OtE #24 🔗 we described how we use stories to model the world around us and how, similarly, AI models use embeddings to create their models. That’s one point of similarity between us and LLMs.
On the other hand, what are the limitations of understanding?
I started this book called “Existential Physics: A Scientist's Guide to Life's Biggest Questions“ by Sabine Hossenfelder🔗, and she says maybe quantum mechanics is the hardest thing to understand for us humans.
Quantum mechanics does not make sense to us humans, we just go wherever the mathematic equations are taking us, exactly like the rule book in the Chinese Room. But we are making progress in quantum mechanics, and we’re using it, how can we not understand it?

My conclusion is that “understanding“ is not the right question to ask, and it’s better to ask either LLMs are able to model the world around them. I’d say yes, they can model the world and if that is the definition of understanding, so they understand what they’re saying, they’re not just generating random text.
LLMs are extremely good at articulating to a point that they can be used as a replacement for language itself. Everyone can have their own LLM, and these LLMs talk to each other for menial and small tasks.
There’s also the question of consciousness that has the same angle: it’s not the right question to ask because we can’t detect consciousness. Like understanding, consciousness can not be analyzed based on input and output.
Think of a hammer. A hammer extends our strength based on the laws of physics like this:
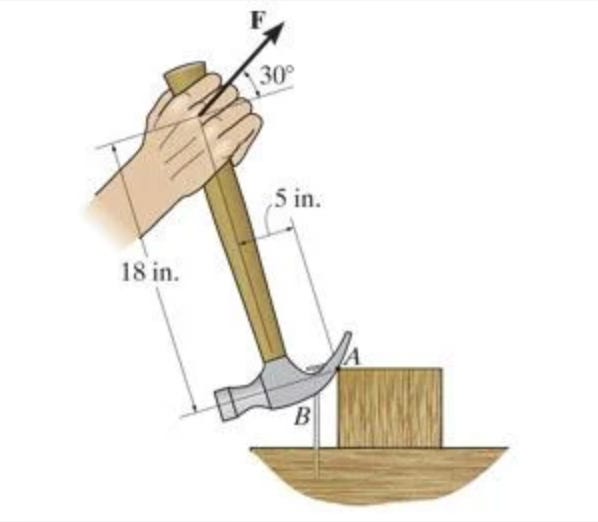
It changes the way we define strength because it’s not the same strength that we call for our muscles. It changes the meaning of strength.
Meanwhile, a hammer doesn’t need to be a magical hammer to change the meaning of strength:

Same with LLMs, they change our definitions of understanding, consciousness, memory, communication, and intelligence. They are powerful, but they don’t need to have collective intelligence or be creative like Shakespeare to be strong AI or AGI.
ChatGPT was really good at writing essays and question-answering, and GPT-4 is really amazing at coding and doing mathematics. Almost all mid-level software tasks can be done by GPT-4. But at the same time, it’s not a threat to talented novelists and software engineers.
The more Internet gets filled with artificial content, the more people will look for authenticity, so finally, there might be a chance for On the Edge with its hasty tone and not-edited text.
It is scary and exciting at the same time to have a new intelligent thing among us. For this new thing, there are new risks. There are many scenarios in that things can go wrong, and they will go wrong.
We’re not able to see how LLMs change privacy, system security, financial markets, and other areas. It is already being misused, and OpenAI had to bring it down on Monday to prevent privacy issues:

Even if it’s not AGI, it has other capabilities and can be misused by humans or even have its own goals, its own understanding. That’s why I don’t agree with Yann.
Three
With all these capabilities, soon we all have access to personalized assistants, and intelligent apps will pop up every day that would be hard to even keep up. It will give us personalized financial advice and medical advice, and of course, the more you pay, the better service you’ll get. Financial markets and medical advice are too broad to think about for now, but two other fields that are immediately changing are education and productivity.
Education
Students and professors have already begun to use ChatGPT heavily for different tasks, and it’s amazing to learn a new topic. A totally new experience of learning will be completed by new open-source movements in education.
In the past decade, the growth of online education was not unknown to anyone, and you can find high-quality material for nearly any topic. For example, this amazing course on computer science was by far better than most of the university materials I’ve seen 🔗.
Connecting LLMs to all these materials will bring free or near-free education at scale. Methods like this🔗 where you use questions to teach, or this one🔗 that uses evidence-based teaching strategies that improve learning significantly, are key disruptors of the field. And kids quickly learn to use these new tools, let alone students, researchers, and professors.

Universities will become more of a place for networking and discussion rather than just participating in a class. People with different interests will form better communities instead of trying to get in the shape of current universities, and good teaching will go toward mentorship and coaching.
Productivity
A considerable part of the current world economy is on content creation, planning, coding, and similar tasks that require full human attention and involvement. The impact of current LLMs on these aspects is larger than it seems.
Harnessing all that power, creating the right tools for LLMs, and educating people will take time, but also the impact is large. Take this research from GitHub, for example, that shows “the treated group that has access to GitHub Copilot was able to complete the task 55.8% faster than the control group.” 🔗 .
Even a 5% improvement in overall productivity boost on normal growth has a disruptive effect on the GDP of countries and the world economy. The concerns here are that these technologies are coming only from developed countries, and they have the characteristic to also boost wealth disparities. That’s the reason that these models are strategic and will become political.
Four
This part is the routine On the Edge.
OpenAI has introduced ChatGPT plugins 🔗 that allow the connection of the model to other apps and data. Use cases are endless, the main plugins are Internet browsing and code execution that OpenAI published themselves. They also published an initial set of 3rd party plugins.
With Internet browsing, you can feed the content straight from a URL or ask questions that need Internet, which was closed before.
With code execution, you can run the code inside ChatGPT, which you had to copy/paste into your own IDE before.
3rd party plugins currently support Expedia to book and manage your flights, hotels, etc., or Instacart to buy groceries and other plugins like this. There are only 11 3rd party plugins officially for now, but there are way more unofficially, and it will increase exponentially.

One of the interesting plugins is the connection to WolframAlpha, which is a popular and powerful tool among researchers for different types of analysis🔗. This allows ChatGPT to turn our question into analytical queries and run it on WolframAlpha.

FFMpeg plugin: this is not official yet 🔗 it allows video editing to be extremely easy. It also demonstrates that many other command line tools can be used by just talking to them.
Another important aspect of the plugins is when you want to create a plugin 🔗. You just write your description plugin in a human language description for everything, and that’s it. You let the model learn how to authenticate to a service, call databases, process data between processes and format it as you want. You don’t need to write code for it. This is absolutely not efficient, but the most impressive approach I’ve seen in computation in my entire life.


Not related to plugins, but OpenAI open-sourced their evaluation metrics 🔗 which is an important step for other companies to benchmark.
OpenAI is in a mode similar to years when Google was launching Gmail, Chrome, Android, Google Docs, etc.
Microsoft announced 365 Copilot 🔗 it allows to use of AI in Word, PowerPoint, Excel, Teams, etc.

Microsoft also introduced Bing Image Creator 🔗


Although Apple has not published an LLM yet, they introduced a technology that runs transformer codes on Apple chips. This is a strategic move because all Apple products, from laptops to iPad and iPhones, have these chips, and they are the only player in the market that has this computation advantage.
Adobe launched their image generation tool called Firefly 🔗 (and it works well).
In the last post, OtE #29 🔗 I was thinking about Nvidia, and this week they announced the Nvidia AI foundation 🔗 where they provide cloud infrastructure for three main products: text (NVIDIA NeMo), visual content (NVIDIA Picasso), and biology (NVIDIA BioNeMo). So far, all of our predictions have been met. We need to be creative about what’s coming because, from this moment on, it’s exponential growth.
One of the releases we didn’t mention before is Anthropic Claud. Anthropic is an AI company that’s focused on AI safety, and it’s backed by Google. Claud is their LLM 🔗 and in some tasks, e.g., question-answering showed better benchmarks than GPT-4
Prismer: An interesting paper that, instead of adding expert knowledge to the whole model, has used domain-specific experts, reduced training time by two orders of magnitude, and had the same performance as the current state-of-the-art 🔗
LangChain: This is also a useful tool that connects LLMs to other apps and data sources. Feed your database into an LLM and ask questions about your data 🔗
Unreal has released a new tool that turns a video recording from a phone into a 3D model of the person 🔗

In OtE #16🔗 I talked about how France is an amazing country with their political stance, freedom, clean energy, and their protests. They’re doing it again 🔗 🔗 .

A Biennale in the ghetto 🔗
Magnolia blooms

Times of silence 🕸️🌈🔗, Show me who's real? 🐦🚁🔗, You're natural 🌈🐥🔗, Soft morning rain🔗, The 🚁 is back or this is his girl?🔗, Moments🔗
This interview with Orson Welles, 1960s, about Citizen Kane. He explains that in those days (1941), all recordings were being watched by the studio, bankers, and distributors! So he leaves the revenue money of the film to them but gets a contract not to allow anyone to see the movie before its release. And explains that he didn’t do it because he was confident but because he was ignorant of money and he loved the movie 🔗
Let’s see this movie before the next On the Edge:

Playlists (I made the 126 as a background when I read and work)



